虽然 ChatGPT 今年才开始爆火,但人类对「对话式人工智能」研究已久(最早追溯到 1970 年代),投入资源也非常大,但是对话式人工智能仍然被视为最难攻克的人工智能技术之一。
这里记录过去一周,我看到的值得分享的东西。
周刊开源(Github:wmyskxz/weekly),欢迎提交 issue,投稿或推荐精彩内容。
题图

5 月 25 日以来,刚进入小麦收割季节的河南遭遇“烂场雨”,严重影响当地小麦的正常成熟收获。6 月 2 日,人民网记者走进河南的小麦主产区漯河市,实地探访河南小麦抢收现场。
本周讨论:ChatGPT 小白向原理解释
(本文参考:【小白向】详细原理解释 | ChatGPT Tutorial 101)

虽然 ChatGPT 今年才开始爆火,但人类对「对话式人工智能」研究已久(最早追溯到 1970 年代),投入资源也非常大,但是对话式人工智能仍然被视为最难攻克的人工智能技术之一。
这主要是因为:
- 人类的语言本身就充满了不确定性,存在着大量的歧义和模糊;
- 人类的对话非常依赖上下文,同样的语句在不同的上下文中可能有完全不同的含义;
这也是为什么各大科技公司推出的智能音箱,会被大家戏称为「人工智障」的原因(当然还有语音识别的问题)。
然而,ChatGPT,一种基于 Generative Pre-trained Transformer(GPT)的语言模型,却在这个领域取得了显著的进步。

这个模型最初由 OpenAI 在 2018 年推出,从那时候开始,OpenAI 一直在对模型进行改进,目前已经发展到了第四代。
GPT 原理最简单的解释
如果要用一句话来简单地解释GPT的原理,那就是:“每次计算出一个词”。无论ChatGPT接收到的文本是什么,它都是在尝试为已有的文字生成一种“合理的延续”。
你可以想象一下,有一台超级计算机,扫描了所有人类的文本之后,可以预测出每一段话后面最可能出现的单词是什么。ChatGPT实际上就是在做这样的事情。
我们可以假设一个填空题,「AI 最擅长的能力是___」。ChatGPT 会算出一个可能的单词排名列表,并计算合理的“概率”:

当每一次 ChatGPT 填好一个词之后,会立马再次启用这个逻辑:

于是在一次一次的任务重复之后,ChatGPT 完成了一整个长句。
当我们向 ChatGPT 提问之后,它其实是在用我们的问题作为起点,一个词一个词地填出答案来。
这里延伸出一个 Prompt 技巧:零样本提示。也就是说不需要给 AI 模型提供任何示例,它也可以较好地完成任务,示例如下:

概率怎么计算?
这个过程并不简单。一种直观的思考方式是,通过统计每个字在所有文本中的出现频率来获得概率。但如果这样做,那么整个句子中就会充斥着高频词,比如在中文中,就是「你我他」、「是」、「不是」等词。
那么,我们再进一步,可以统计每个词在一段特定长度的句子后出现的频率。我们来看两个例子:
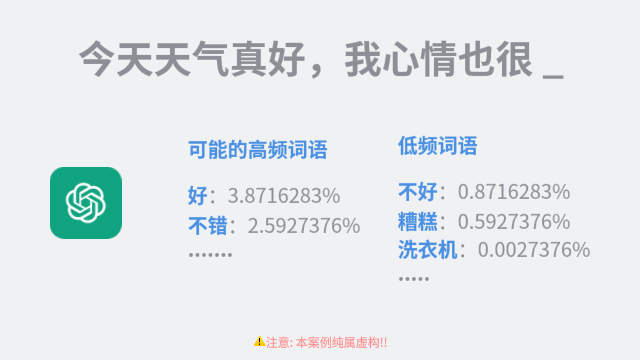
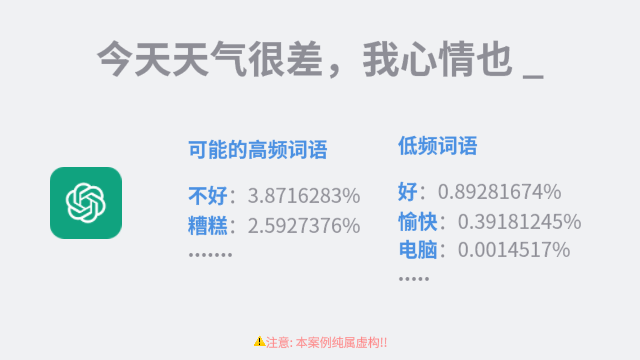
对于 ChatGPT 来说,读完前面的句子后,直接取下一个出现概率最高的词就好。
所以这里又出现了另外一个问题:计算量太大。
为了让 ChatGPT 见过尽可能多的单词组合,在 ChatGPT 所使用的训练数据集里,光网上爬下来的就有几百亿个单词,再加上书里的单词,总计可能有几千亿个单词。
如果我们要计算每个单词在一段话后的频率,这个计算量就会呈指数级增长。如果每个单词前面的句子超过 10 个词,可能需要的计算量会超过地球上所有计算机的总和,甚至可能需要计算到宇宙毁灭。
为了解决这个问题,科学家们引入了模型,也可以称之为算法,或者更简单的说,函数。
我们回想一下,初中物理课上学的抛物线是怎么算的。

一个小球从地上被往上抛起,我们并不需要每次改变一点点条件就都要去重新测量小球上升或者下降了多少米,我们摸清楚它的规律之后,总结了一个函数:
1 | y = ax^2 + bx + c |
根据不同的情况,我们给参数 a、b、c 赋予不同的值,就可以根据 x 计算出 y 的值。
同样的,我们可以将上面那个需要计算到宇宙毁灭的任务理解为一个要去计算一个更复杂的抛物线。在这里,x 是「今天天气真好,我心情也很_」,而 y 是「不错」或者「糟糕」等特定单词出现的概率。
为了计算出每一句话之后每一个单词出现的概率,我们现在不是要去真的计算每个词每个句子,而是尝试去总结一个函数出来。
这就是 ChatGPT 的基础结构,一个函数。只不过,这个函数有一些特别的地方。在 OpenAI 公开的研究内容中,GPT-3 模型有 1750 亿个参数。我们并不能像计算抛物线一样,人工地给 abc 赋值,因为这是 1750 亿个参数。这时,神经网络就派上了用场。
神经网络
在许多领域,我们都面临着解决「复杂函数」问题的挑战,例如图像识别。因此,科学家们开始借鉴大脑的结构来解决这些复杂函数问题。
从字面上看就知道,神经网络是在计算机中模拟大脑的工作方式。
当我们观察人类的大脑,可以看到,大脑基本是由神经元组成的,然后在神经元之间有一个薄弱的连接,电信号在其中传播,大概是这个样子:
对于任何一个神经元来说,它周围的各个方向都有连接,然后神经元通过这些连接接收上一个神经元传递过来的信号,处理后再将信号传递给下一个或下几个神经元。
当所有的神经元作为一个整体运转时,它就构成了你的大脑。比如当我们的右脚小拇指撞到桌腿,或者看到路边的一只可爱的小猫时,我们的身体将接收到的信息转化为电信号,然后发送到大脑和大脑神经元,相关的神经元就会被激活,被信号击中,然后传播到下一个连接的神经元,最终在你的大脑中产生感觉、思考或结论。
计算机科学家们将这一整套的大脑运作机制简化成了一个非常简单的模型,我们先关注某一个特定的神经元,假设这个特定的神经元收到了一个信号。
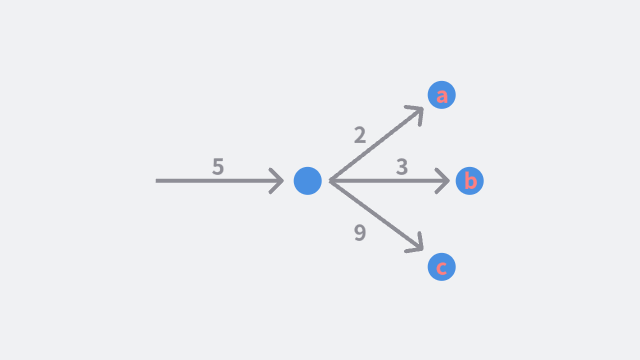
我们将信号的强度从 0 到 9 进行排序,0 代表非常弱,9 代表非常强的信号,而此时,我们这个神经元收到了强度为 5 的信号,经过简单的处理,它决定将信号 2 发给神经元 a,信号 3 发给神经元 b,信号 9 发给神经元 c。
假设这个神经元是最后一个输出的,而 abc 是一个选择题的三个选项,那么这个神经元对于信号的答案就大概率是 c。
就这样,我们完成了一个最基础的神经元模拟。
如果我们再创建许多这样的神经元,将它们堆积成层,然后一层一层地叠加起来,就构成了我们人造的神经网络。
虽然它是简化的单向版本,不像真正的大脑那样,神经元还可以将信息传回给之前已经传递过信息的神经元,但目前这个神经网络已经可以开始运作了,最早的神经网络成功案例就是图像识别。
比如,我们要判断一张图片里是否有猫,将这张图片以像素的方式输入神经网络后,神经网络会一层一层地开始激活,也就是传递电信号,最终在结果层告诉你答案。
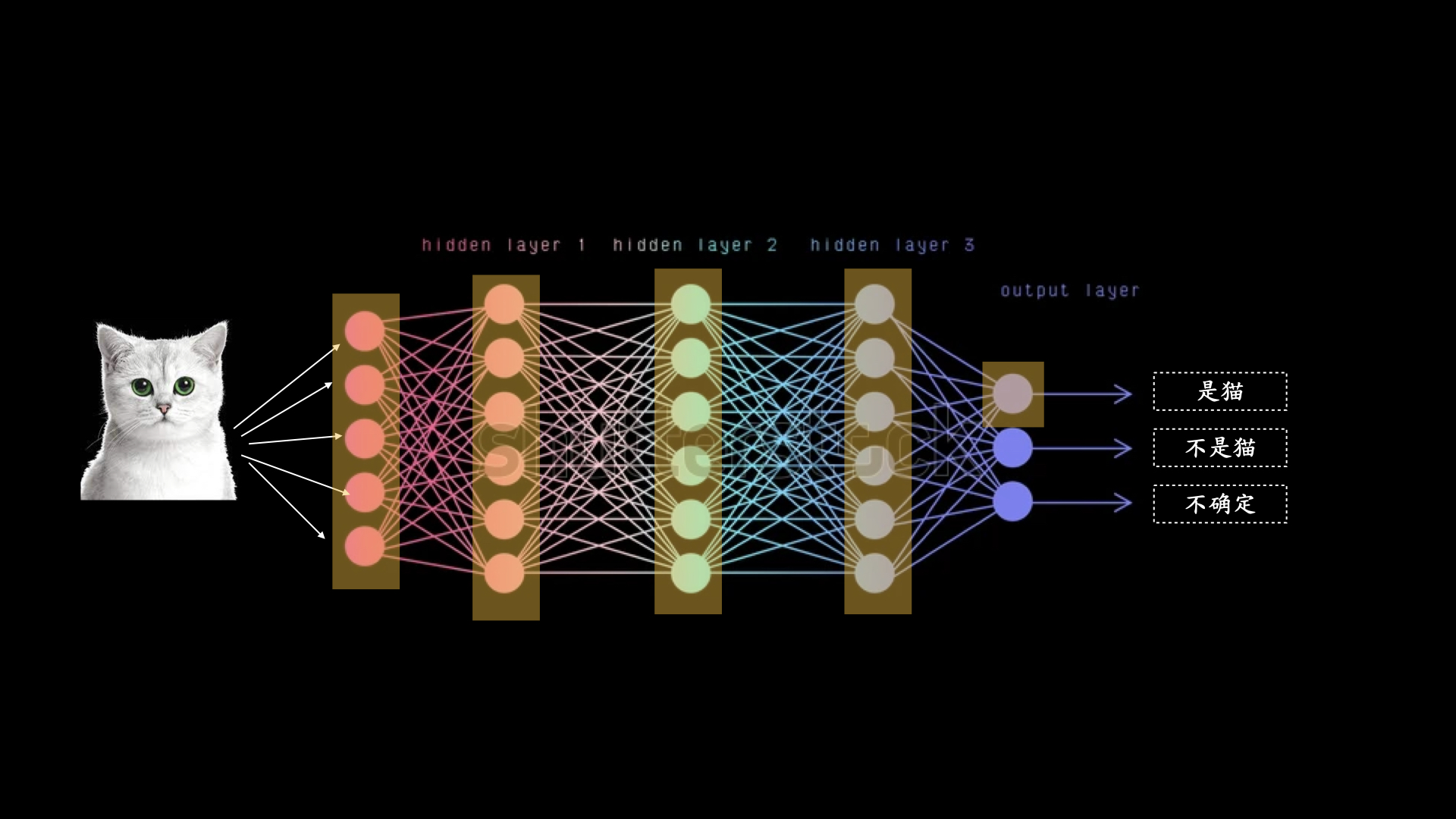
然而,我们不能仅仅随便搭建一个模型,就期望它能直接给出正确的答案,我们需要对其进行训练。
训练
就像我们在教育小孩的时候,会一遍一遍地告诉 ta,哪个是小汽车,哪个是小猫咪。对于神经网络也同样如此,我们会先拿出几万张甚至几十万张猫、狗、猪、洗衣机、微波炉的照片给它,并告诉它正确答案。
在每一次的训练中,它都会稍微改变一下神经元们激活的路径,直到一次又一次的训练后,这个神经网络神奇地学会了怎么识别猫,每一次不同的图片传输进来,它好像都能够找到正确的信号激活路径然后给出正确答案。
我们也许可以说神经网络正在“挑选某些特征”,比如尖耳朵,并利用这些特征来确定图像的内容。但这些特征是比如“尖耳朵”这样的我们可以描述出来的特征吗?
大多数情况下并不是的。大多数情况下我们没有一种“给出叙述性描述”的方式来描述我们大脑的推理方式,或者说神经网络正在做什么。这也是为什么都在说现在的 AI 是不可解释的,是黑盒子。

著名学者兼企业家 Wolfram 对此说道:
也许这是因为它真的是计算上不可简化的,没有一般的方法可以找出它的行为,除非我们明确地追踪每一步。或者也许只是因为我们还没有“找到科学方法”,并确定了“自然法则”,使我们能够总结正在发生的事情。
但 Anyway,我们这种人造的神经网络在经过大量训练之后,可以开始识别出猫了。
而当我们回到之前聊到的 ChatGPT 所使用的复杂函数上来,神经网络也同样被应用到了构造那个复杂函数上。
总结
这里没有花篇幅来介绍训练的两种模式(一种无人工监督自主学习,另一种人工监督矫正),但总之,完成了各种训练之后,那个 1750 亿参数的函数也就被训练出来了,而机器也可以开始正确地选出下一个词是什么了,那么一个 ChatGPT 也差不多就成型了,成为了当下这个令人震惊的对话式人工智能。
其实在算法层面上没有什么颠覆式的突破,但是数据量的增加带来的一切太出乎意料了。据说 OpenAI 内部对于提升数据量之后这股「涌现」出来的能力也感到非常惊讶,就好像忽然突破了某个阈值,AI 就进化成另一个新物种了。
正如微软研究院各位科学家所最新出的一篇叫做《Spark of Artificial General Intelligence: Early Experiments with GPT-4》的论文,我们在 GPT-4 身上看到了通用人工智能的星星之火。
热点新闻
1、「人工智能可能灭绝人类」,350 位 AI 权威签署联名公开信

350 位 AI 行业的权威本周二发出联名公开信,称当前正在开发的人工智能技术可能会对人类构成生存威胁。
签署人包括三个领先的 AI 公司高管:OpenAI 首席执行官 Sam Altman;Google DeepMind 首席执行官戴米斯·哈萨比斯;以及 Anthropic 的首席执行官 Dario Amodei;另外还有杰弗里·辛顿和约书亚·本吉奥这两位人工智能的「教父」。
这封信只有一句声明:降低人工智能灭绝的风险,应该与其它社会规模的风险(如大流行病和核战争)一样,成为全球的优先事项。

6 月 1 日,阿里云正式宣布推出一款名为「通义听悟」的音视频内容 AI 新产品,它基于通义大模型,目前已正式上线,这是国内首个开放公测的大模型应用产品。
据介绍,「通义听悟」结合了通义千问大模型的理解和摘要能力,可帮助用户高效地完成对音视频内容的转写、检索、摘要和整理。
阿里云的 CTO 周靖人表示,「通义听悟」是一款工作学习 AI 助手,专注于具有高附加值的音视频内容场景,例如会议、课堂、访谈、培训、面试、直播、观看视频和听播客等。它利用大模型和其他最新的 AI 技术,能够快速提取和沉淀知识。
3、最危险的儿童玩具(英文)

说到真正危险的玩具,您很难击败吉尔伯特 U-238 原子能实验室。该套件标榜为“令人兴奋且安全”,包含四个密封罐,其中装有真正的铀矿石(具有放射性)。该套件由 AC Gilbert Toy Company 制造,于 1950 年上市,售价为 49.50 美元(按今天的货币计算超过 500 美元)。
那是二战后,原子及其所有未被发现的潜力的时代。那也是一个几乎没有消费者保护法的时代,因此没有什么可以阻止让孩子们参与原子能热潮的机会。
文章

文章的作者分享了如何通过改变环境来降低启动成本,从而更有效地实现目标。他强调了大多数人的决策并非深思熟虑,而是遵循直觉和习惯,因此,我们的行为模式和生活习惯往往决定了我们的生活。
他建议我们通过有意识的设计,让我们处在一个良好的环境之中,让周围的一切成为我们的助力,降低我们的启动成本,引导我们去选择我们想要的行为。这篇文章对于想要更有效地实现目标的人来说是非常有帮助的。

这本书的作者是澳大利亚的院士、澳大利亚、意大利、美国等多所大学的医学及营养学教授,他在《科学》、《自然》、《细胞》等顶级期刊发表了130多篇高频引用的论文。
所以兄弟们,码住,遗忘的时候再看一遍!
书中说,人类健康有四大杀手:吃的不对,吃得有点多,久坐,精神压力。这四大杀手导致人们获得慢性疾病,从而影响寿命。
要想长寿,你必须正面这四大杀手,难度最大的是第一个,花时间最长的是最后一个。戳文章仔细看看。
PS:兄弟们,一定码住,相信我,未来值得你再健康多活几十年。
3、四十年的职业生涯(英文)
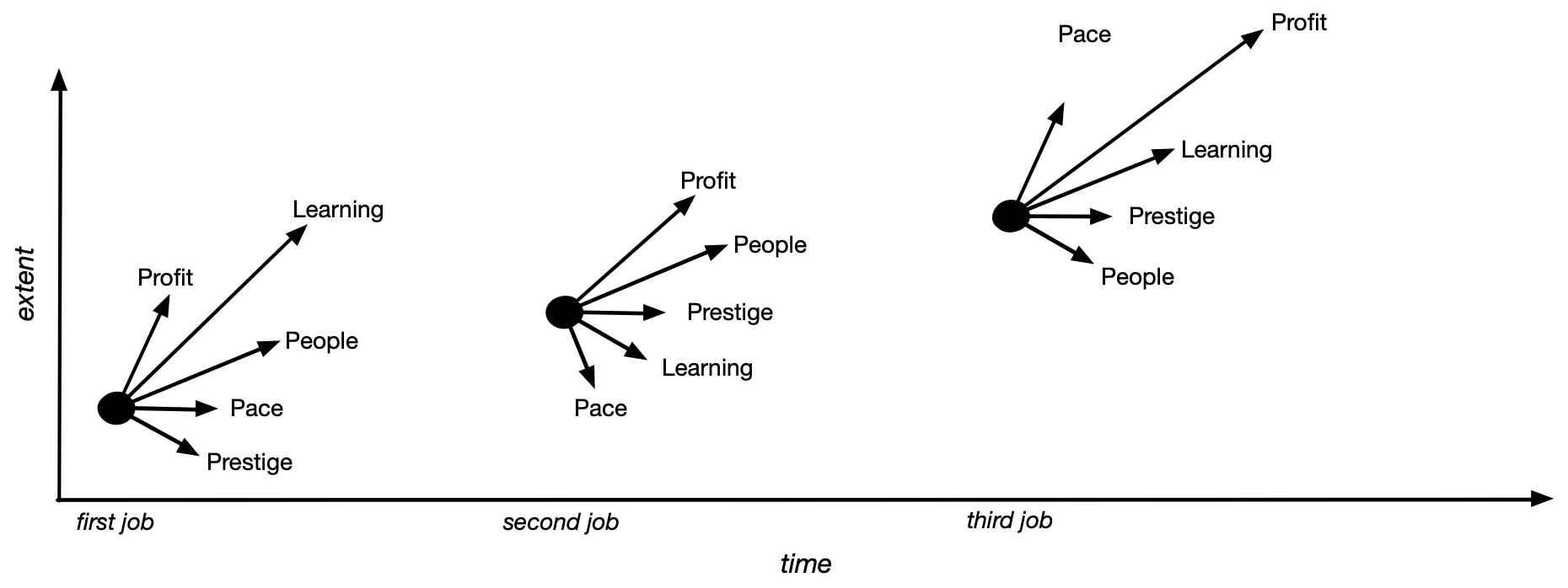
作者Will Larson分享了他对于长期职业生涯的思考。他强调了如何通过管理工作节奏、建立人际关系、积累声望、保持经济稳定和持续学习来实现职业生涯的长期发展。
他认为,这些因素都是相互影响、相互促进的,只有当它们一起作用时,才能实现职业生涯的成功。这篇文章对于那些希望在职业生涯中实现长期成功的人来说,是一篇非常值得阅读的文章。
4、信仰高于逻辑(英文)
作者 Erik Torenberg 探讨了在生活中做出重大决定时,如何在理性和信仰之间找到平衡。他指出,尽管我们通常倾向于使用理性来做出决策,但在很多情况下,这种方法可能会导致我们陷入无尽的优化和决策困境。
相反,他提倡我们在做出重大决定时,比如选择伴侣或创业,应该更多地依赖于信仰,即使这种信仰在某些时候看起来并不合理。
他强调,这种信仰并不是盲目的,而是需要我们有意识地选择,并在困难时坚持下去。他认为,这种对信仰的坚持,最终会带给我们更深层次的满足感和幸福感。
这篇文章对于那些正在寻找生活方向或面临重大决定的人来说,提供了一种全新的思考方式。
5、开发人员认知负荷指南(英文)
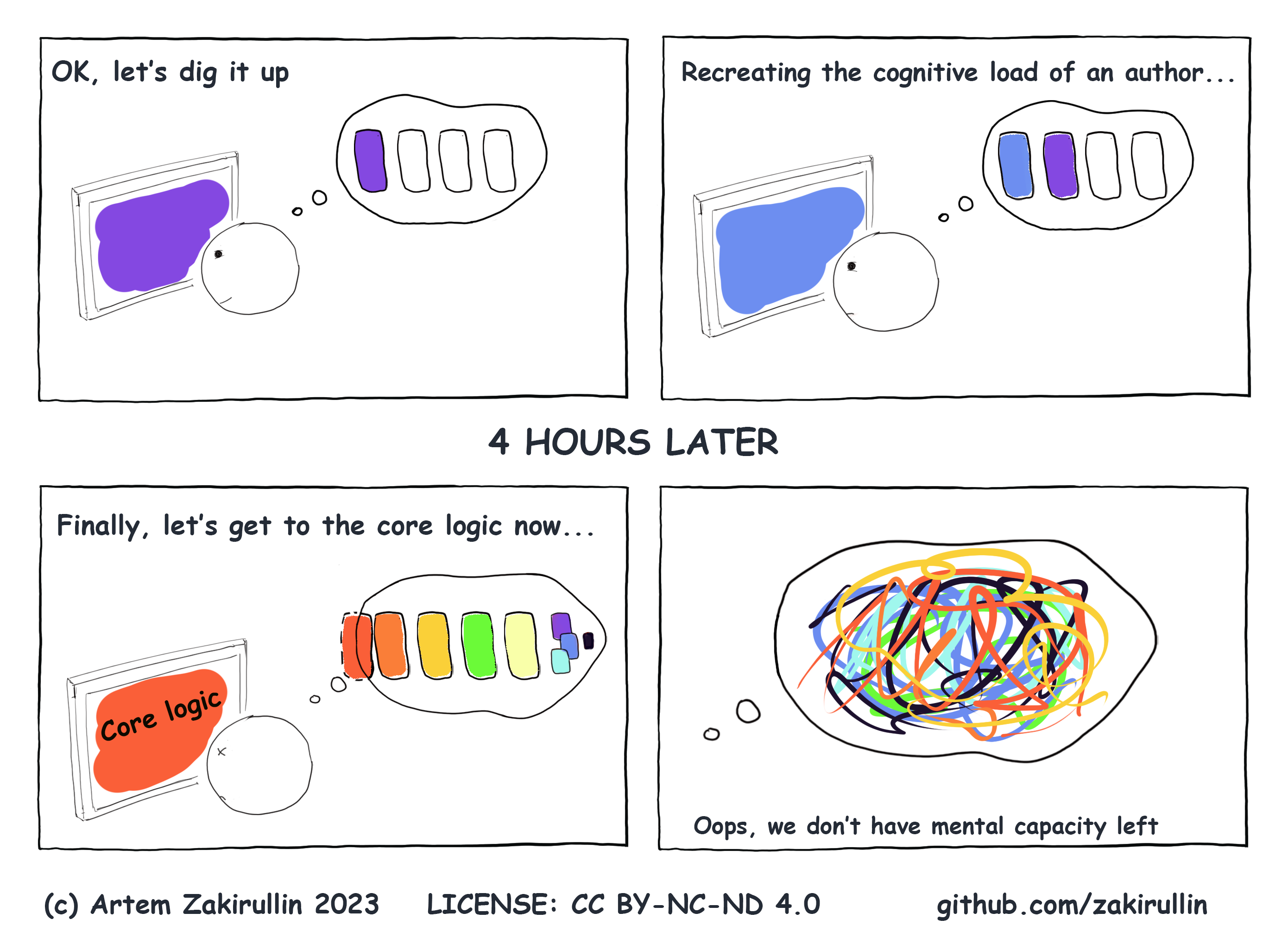
这是关于如何在软件开发中管理认知负载的指南。它讨论了认知负荷的概念,并提供了如何在软件开发的各个方面(如代码可读性、架构设计和问题解决)减少认知负荷的实际示例。
该指南强调了减少不必要的认知负荷以使软件开发更有效和可管理的重要性。
6、以星巴克咖啡的成本训练您自己的私人 ChatGPT 模型(英文)

这篇文章介绍了如何使用 Apache DolphinScheduler 训练自己的 ChatGPT 模型——仅用一杯星巴克咖啡的钱(这算不算变向抹黑星巴克咖啡贵啊?)。作者详细解释了整个过程,并提供了一些实用的建议。
7、聪明的代码被认为是有害的(英文)

这篇文章讨论了编程中的 “聪明代码” 的问题。作者认为,虽然这种代码可能在短期内看起来很酷,但在长期内,它可能会导致代码难以理解和维护。作者建议开发者应该编写简单、清晰的代码,而不是追求 “聪明”。
8、OpenAI创始人Sam Altman的高效秘诀:如何管理自己的精力,提升工作生活的效率?

如何在工作与生活间找到平衡?如何优化全年工作而非仅关注日常效率?如何通过制定清单集中精力并合理安排时间?如何在任务管理中找到适合自己的方法?睡眠、锻炼和饮食如何影响我们的生产力?
这里是关于OpenAI 的创始人 Sam Altman 对于上述问题的思考。

文章讨论了现代数字工具如何使我们能够轻松地从各种来源获取信息,但真正的挑战在于如何让这些信息穿越时间周期。
作者提出了”第二大脑”的概念,这是一个外部的、集成的数字仓库,用于存储你学到的东西以及它们所来自的资源。
文章还介绍了PARA方法,这是一个全面的信息管理系统,它能够整理所有类型的数字信息。
最后,文章提出了以笔记为主的知识管理方法,强调了设计易于发现的笔记的重要性。这篇文章对于那些希望提高信息管理和笔记效率的人来说是非常有价值的阅读。
好奇星人
本周暂无;
言论
1、
人们常说人工智能没有人的灵魂、人的感受,这不过是一个自我安慰。人自己的灵魂、感受,也是很多神经元细胞连接成复杂系统后涌现出来的。
未来科幻作家不会彻底消失,但会沦为非主流,类似于现在的皮影戏,人们的科幻创作会一直存在,但他不会成为那种一直受关注的主流内容。
–刘慈欣
2、
不要问世界需要什么。问问是什么让你活过来,然后去做。因为世界需要的是活着的人。
–霍华德瑟曼(英文)
3、
对于你心中未解的一切,请保持耐心,试着去爱这些问题本身,就像爱上那些上锁的房间,或者用一种非常陌生的语言写成的书一样。不要现在就寻求答案,因为你无法得到答案,即使得到了你也无法活出它们。重要的是,要活出一切。活出这些问题吧。也许有一天,在遥远的未来,你会在不知不觉中,活出答案来。
–莱纳·玛丽亚·里尔克(英文)
4、
创造者经济中最普遍的建议是缩小利基市场。让自己沉浸在一种亚文化中。选择一个主题。拥有它。专攻。因一件事而出名。
如果您的目标是在网上创造东西,并以某种可靠的方式谋生,那么选择小众市场是一个明智的选择。
–小众化的危险(英文)
5、
彩票的热度确实有所提升。近期,财政部数据显示,今年 1-4 月累计,全国共销售彩票 1751.5 亿元,创五年来同期新高,同比增长 49.3%。
对一部分年轻人来说,彩票不仅仅是财富的诱惑,更带来了生活乐趣和仪式感。刮彩票成了年轻人舒压的新方式。
订阅
微信搜索”我没有三颗心脏”或者扫描二维码,即可订阅。
